 Udfordringen er velkendt og uændret: Kunderne ønsker hurtigere, smartere, lettere og bedre kundeservice. For virksomheder og organisationer er målet at skabe høj kundeværdi og produktivitet – samtidig. Defineret som en afvejning af Kvalitet, Service, Omkostning og Tid.
Udfordringen er velkendt og uændret: Kunderne ønsker hurtigere, smartere, lettere og bedre kundeservice. For virksomheder og organisationer er målet at skabe høj kundeværdi og produktivitet – samtidig. Defineret som en afvejning af Kvalitet, Service, Omkostning og Tid.
- Kvalitet: Opfylde kundens behov, procesintegritet, minimal variation, spildreduktion og løbende forbedringer (tilpasninger ift. kundernes behov).
- Service: Levere kundesupport, produkt/service-support, fleksibilitet ift. kundes ønsker og ændringer i markedsbehovet.
- Omkostning: Reducere omkostninger inden for produktudvikling og engineering, materialer, kvalitetssikring, distribution/logistik, lager og administration.
- Tid: Reducere Time to market og New Product Introduction (fra idé til levering), leveringstid (fra bestilling til levering) og den interne gennemløbstid.
En velkendt produktivitetsmetode, der balancerer Kvalitet, Omkostninger, Service og Tid ved at skabe en drift, baseret på velfungerende værdikæder, er Lean. Driveren i Lean er procestilgangen og genstandsfeltet er værdistrømmen, hvor tiden bliver den afgørende faktor.
Et af de store bidrag, der kom med Lean, var kortlægningen af processer, kunderejser og værdistrømme efter Value Stream Mapping metoden. Det kan begrundes med den ’aha-oplevelse’, en kortlægning tilvejebringer. Det bliver tydeligt, hvad kunderne udsættes for, og hvor meget spildtid og unødvendige ansvarsskift m.m., der indgår i kunde-rejsen. Traditionelt kortlægges værdistrømmen i en workshop, udført med papir og blyant.
Det særlige ved Value Stream Mapping (VSM) i forhold til andre kortlægningsmetoder er, at styringsflowet også medtages, således at man kan se, hvordan arbejde igangsættes, og i hvilke mængder, samt hvor meget lager der befinder sig mellem de enkelte processer. Samme data findes også i ERP systemer, men her er det svært at skabe et processuelt overblik, og herved se, hvor flaskehalsene i den enkelte værdistrøm er. Det tillader VSM.
VSM har begrænsninger
Selv om VSM kan fremvise adskillige fordele, har VSM også begrænsninger. Særligt kan VSM være udfordrende, når produkter eller processer er komplekse, og det ikke via f.eks. Lean metoder er muligt at reducere kompleksiteten markant. Et produkt eller en service består af mange dele og underenheder, der følger forskellige ruter og processer. For eksempel havde møbelfabrikken Tvilum-Scanbirk i 2008 43.000 mellem-varenumre og over 400.000 materialebevægelser daglig. Hvert varenummer havde sin egen værdistrøm. En anden trævarebaseret fabrik håndterede 18.000+ komponenter. Her tog det 3½ måned at kortlægge de underliggende processer. Desuden lancerede virksomheden 1-2 nye produkter pr. dag, hvilket gjorde kortlægningsindsatsen ufuldstændig og ikke længere retvisende. Kompleksiteten synliggøres ved en komplet oversigt over værdistrømmene – kaldet et ’spaghettidiagram’. Nedenstående eksempel viser et spaghettidiagram, jf. figur 1.

Figur 1: Eksempel på den komplette værdistrøm – eller spaghetti-diagrammet som det ofte benævnes.
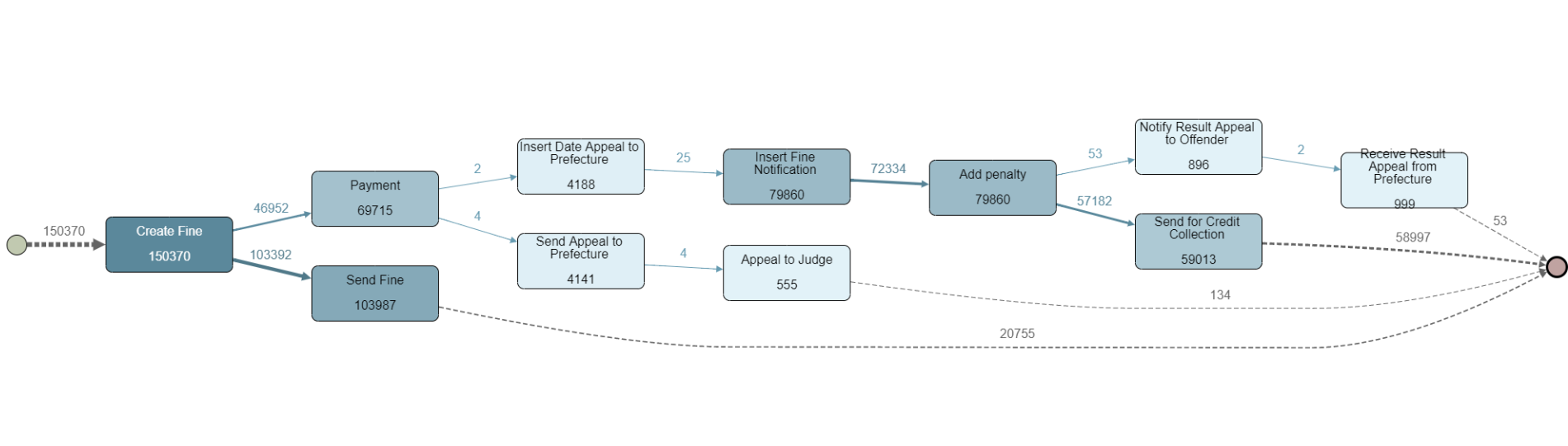
En VSM vil typisk kun vise hovedflowet, som det fremgår af figur 2.
VSM blev skabt hos Toyota som et værktøj til at analysere specifikke værdistrømme, der var klart definerede. I en virksomhed med f.eks. en væsentlig del ordreproduktion og skiftende produktprogram, vil brug af VSM typisk kun ’beskrive’ toppen af isbjerget – de kendte hovedprocesser (jf. figur 2). Afvigelser, alternative processer og ’gedestier’ bliver ikke beskrevet med denne metode, og VSM giver ikke et tilstrækkeligt helhedsbillede af den reelle AS-IS-situation i virksomheden (som er udtrykt i figur 1).
Process Mining som mulighed
De interne processer og logistikken inden for bl.a. samlebåndsproduktion er kendetegnet ved en lang række automatiske aktiviteter (logistikprocesser, ressourcer og kapacitetsplanlægning). Pakkematerialer, forbrugsvarer, følgesedler osv. tilføres båndet automatisk, vha. ERP/it-systemer. Under den operationelle udførelse, registrerer it-systemerne hændelserne som log-filer. En log-fil henviser til en aktivitet og et tidsstempel. Disse hændelser opfanges kun sjældent i forbindelse med en analog kortlægning af værdistrømmen.
It-systemerne, der understøtter f.eks. produktionen (eller sagsbehandlingen i en serviceorganisation, eller patientforløbene i regionerne), skaber som nævnt en enorm mængde log-filer. Den teknologiske udvikling (inden for CPU/regnekraft) har medført, at der er udviklet en række metoder (algoritmer) til at analysere disse data. Det kaldes generelt for data mining. Konkret i forhold til at forstå processer kaldes dette Proces Mining (PM).
PM opstod som et forskningsfelt på ledende Business Process Management Universiteter ud fra en teori om, at data (log-filer), der registrerer interaktioner/aktiviteter i processen, kan understøtte ”reverse engineering” af it understøttede eller data skabende processer (ERP, MES, IoT) bedre end tunge transaktionsdata (Big Data). Dvs. denne type data kan bedre repræsentere de sande processer end egentlige transaktionsdata. ’Process mining is a family of techniques to analyze the performance and conformance of business processes based on event logs and other data produced during their execution’. (Marlon Dumas, Professor, Tartu University 2019).
Idéen er, at ganske få datapunkter (CaseID, ActivityID, TimeStamp) kan skabe omfattende og retvisende indsigt i selv meget komplekse (forstået som indeholdende en lang række varianter) procesforløb og værdistrømme som f.eks. Order2Cash, hvor VSM-metoden bliver for simpel og ikke i tilstrækkelig grad fanger variansen. Udviklingen af Proces Mining har skabt en række algoritmer og teknikker, der primært dækker de tre områder (der uddybes senere i artiklen): Process Discovery (opdagelse), Avanceret Proces Analyse og Conformance Analyse.
VSM – digitalt via Proces Mining
Til trods det umiddelbare enkle i at omdanne log-filer (fra fysiske transaktioner) til brugbare data er det en ganske omfattende opgave at skabe en proces mining. Alle casestudier starter med udvinding og forberedelse af data. Dette omfatter også en rensning af log-filerne. Herefter kan der opbygges forståelse af data og en præstationsanalyse. Præstationsanalysen er altid baseret på tider (f.eks. ventetider, samlet gennemløbstid m.m.). Desuden indgår frekvensen af sager eller aktiviteter, der er blevet undersøgt. Herefter kan PM anvendes i flere forskellige retninger afhængig af formål. En fremgangsmåde er skitseret i figur 3.
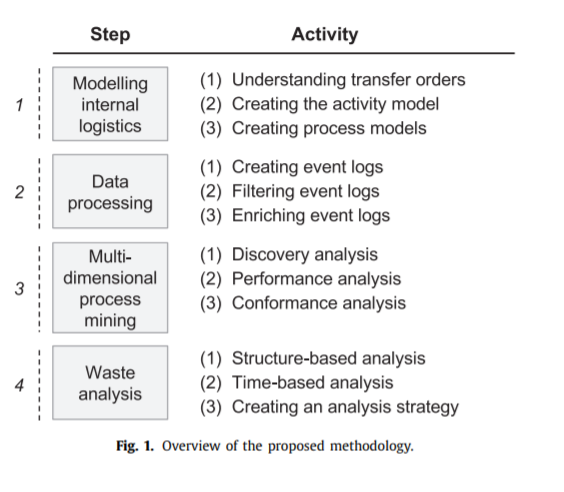
Figur 3: Fremgangsmåde ved Process Mining.
Step 1 – Opbygning af den grundlæggende model
I denne indledende fase, opbygges en grundmodel af værdistrømmen. Erfaringerne viser, at der med fordel kan inddrages analoge metoder her – f.eks. en skitse af den overordnede end-2-end proces, der er i fokus. I denne fase kan PM betragtes som en ’udbygning’ af en traditionel VSM. Derved udvides den analoge og statiske VSM med dynamikken og variansen fra PM. Desuden fastlægges scope, hvilket specielt ift. begrænsning af log-filer er afgørende for at skabe fremdrift.
Step 2 – Data Extraction and cleaning
Denne fase omfatter en ‘discovery session’, hvor log-filer og log-fil-data identificeres. Det er typisk organisationens it-organisation, samt interne og eksterne systemejere, der i samarbejde identificerer de relevante log-filer. Identifikationen er baseret på beskrivelserne fra første fase, process map, samt scope. Målet er at frembringe de ’rigtige’ log-filer og data for at opnå en tilfredsstillende PM. Det er ligeledes i denne fase, at diverse overvejelser omkring datasikkerhed og rettigheder skal håndteres. Ejerskabet af log-filerne kan være svært at få afklaret og dernæst at få adgang til at arbejde med de faktiske data. PM lider som andre typer af procesforbedringer ofte af manglende ejerskab – hvem ejer de tværgående processer? Ligeledes kan det tekniske omkring data udtræk fra systemerne være ganske besværligt. Ejerskabet omkring log-filer, skabt i diverse it-systemer, kan være vanskeligt, og erfaringerne viser, at ved implementering af it-systemer skal dataejerskabet være fastlagt.
Step 3 – Proces Mining – det egentlige gravearbejde
I denne fase gennemføres den egentlige ’mining’ i den algoritme, der anvendes. Miningen skaber (afhængig af algoritme) typisk tre forskellige output:
- Process Discovery (opdagelse) er første resultat af en Process Mining. Log-filerne er analyseret af algoritmerne, og et process map (diagram) er skabt (se figur 1). Modsat andre procesmodelleringsmetoder kan vi straks observere de hyppigst router igennem aktiviteten, og vi kan aktivere gennemløbstiderne mellem de enkelte aktiviteter.
- Avanceret Process Analyse åbner mulighed for at zoome helt ind på specifikke performance indikatorer som for eksempel at forstå, hvordan processen er påvirket af handover mellem ressourcer (medarbejdere) eller afdelinger. Her kan det anbefales at berige log-filerne med data som ressourcer, kunde, maskine, service aftaler m.v., så modellen kan blive så rig som muligt.
- Conformance analyse er hjørnestenen i den digitale mulighed for at sammenligne en deklarativ (forklarende procesmodel f.eks. beskrivelse af en compliant låneansøgningsproces) med den faktiske eksekvering af processen. Det giver et klart billede af, om forretningsreglerne overholdes i den daglige drift.
Step 4 – analyse og spild
I sidste fase af en PM analyseres de maps, der er blevet skabt. Den eksisterende værdistrøm indeholder spild. Spild af tid, ressourcer, ventetid, lager m.m. Spildet reduceres vha. principperne fra Lean (flow og pull). Med PM anvendes en ’videnskabelig’ tilgang med hypoteser, tests og simuleringer. Hypoteser, idéer og koncepter testes i modellen (digital twin). Hvordan vil gennemløbstiden udvikle sig, hvis kapaciteten på en maskine forøges, eller hvis omstillingstiden reduceres? Hvordan vil svartiden i kundecentret blive påvirket af at udjævne tilkomsten af opkald? Hvor meget ekstra kapacitet skal der tilføres på sygehuset for at kunne følge med i peak-perioden? Hvad vil blive flaskehals ved et ændret salgsmiks?
Den digitale model af virksomhedens netværk af ressourcer og processer giver et komplet overblik med dynamiske tider og kapaciteter. BMW nævner som deres erfaring: ’We can visualize the production processes as they really happen and not as they’ve once been planned’. (Lars Reinkemeyer, 2020). ’Hvad nu hvis…’- spørgsmålene fremsat af de berørte interessenter og aktører kan blive besvaret. Det giver en gennemsigtighed og troværdighed, og et godt fundament for implementering af løsninger og forbedringer i forandringsfasen.
Opsamling og konklusion
Værdistrømsanalysen (VSM) sammenstykkes traditionelt i en workshop med deltagelse fra de afdelinger, der er berørt af processen. Det har en række ulemper, som er fremhævet i denne artikel: 1) Processernes kompleksitet kan ikke beskrives i tilstrækkelig grad. 2) Dynamikken i værdistrømmen lader sig ikke i praksis beskrive. 3) Store dele af værdistrømmen er båret af it-systemer og ’usynlige’ processer, der ikke umiddelbart kan beskrives ved den analoge fremgangsmåde.
It-systemerne, der bærer processerne, har vist sig at være løsningen. Ved at analysere de log-filer, it-systemerne skaber, er det muligt vha. Process Mining (PM) at skabe en digital værdistrømsanalyse. For år tilbage var der visse vanskeligheder ved at anvende PM, f.eks. med håndteringen af de mange data, der dagligt genereres i et it-system. Udviklingen af data-kraft og algoritmer har siden reduceret denne udfordring. PM er dog stadig ganske nyt, men det tager mere og mere fart. I dag findes der således flere og flere teknikker, der gør PM til en ganske anvendelig og Lean understøttende metode. Fremtiden vil kun byde på mere i denne retning.
PM har dog også udfordringer. PM skaber det komplette billede, baseret på data, fakta og samtlige processer. Fordelene er et ’korrekt’ billede/model af virkeligheden. Ulempen er, at ’sandheden’ kommer ud af data og omfatter ALT. Det udfordrer de faglige eksperter, der skal acceptere, at data og algoritmerne ved mere, end de gør. Det kendes også fra BMW (L. Reinkemeyer 2020): ’First of all our […]experts have been quite critical. Why do those IT colleagues think they can solve problems that are hard to tackle for the most experienced and skilled experts in the field?’ Udfordringerne kan dog overvindes: ’[But] as soon as these challenges have been mastered, Process Mining can bring massive possibilities…’.
En anden udfordring, vi har oplevet i forbindelse med PM, er data-kvaliteten. Umiddelbart lyder det simpelt at hente data ud af systemet og omsætte dem til en værdistrøm. Det har dog vist sig, at data ikke i sig selv har værdi. Data skal oversættes og sættes i kontekst for at have værdi. Data skal renses og struktureres, ofte på tværs af afdelinger, og uden et tværgående organisatorisk ansvar for data.
Når det er håndteret, er der omvendt næsten ingen grænser for, hvad PM kan bidrage med. Vi ser et stærkt parløb mellem Lean og PM, hvor PM forstærker VSM-delen i Lean, og hvor Lean kan medvirke til at tolke de modeller, som PM skaber.






















































